If you have infinite resources, you can easily horizontally scale. Meaning: Adding more Elasticsearch nodes or increase the capacities of these nodes. But this is costly and sometimes (actually always) it's better to "clean up" what can be cleaned up first.
One possibility is to avoid indexing log messages which were never meant to be indexed. This could be verbose logging of an application, not helpful to any troubleshooting or creation of statistics.
Logstash drop filter
For this purpose, Logstash has a drop filter plugin. It allows all kind of different matches, even understanding strings and arrays.
A few examples needed?
root@logstash:~# cat /etc/logstash/conf.d/15-filter-nginx.conf
filter {
if "Googlebot" in [nginx.access.user_agent.name] {
drop { }
}
}The first example above uses the field [nginx.access.user_agent.name] coming from Filebeat's Nginx module. If Googlebot matches or is part of the User Agent, the log message will be dropped.
Multiple conditions can be defined, too:
root@logstash:~# cat /etc/logstash/conf.d/15-filter-esxi.conf
filter {
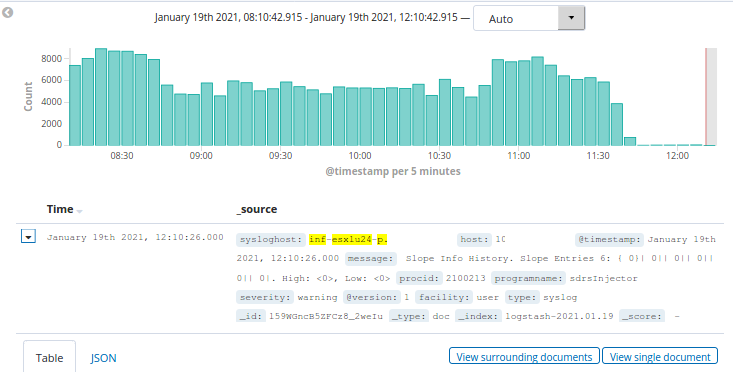
if "esx" in [sysloghost] and [severity] not in ["warning", "err", "crit"] {
drop { }
}
}The example above uses multiple conditions. First the hostname (defined in the [sysloghost] field) must contain the string "esx" in it. Second the [severity] field must not be one of either "warning", "err" or "crit".
Note the string comparison is before the field (string in fieldname) but for arrays it's the other way around (fieldname in array).
Show me the results!
After applying drop filters, the amount of data sent from Logstash to Elasticsearch was significantly less. This not only means less disk space used in Elasticsearch, but also less indexing (= less resource usage).